Apache Spark - Pair RDDs
Introduction
Pair RDD is a common data type in many operation on Spark. Many dataset in real life is usually a key-value pairs. The typical pattern of this kind of dataset is that each row of data is a map from one key to one or multiple values. To working with this kind of data more simpler and more efficient, Spark provides a data structure called Pair RDD instead of regular RDDs. Simply, a Pair RDD is a particular type of RDD that can store key-value pairs. It can be created by converting from a regular key-value object or convert by regular RDDs.
Create Pair RDDs
- From a Python Tuples
my_tuple = ('key', value) # using parallelize method to create def parallelize(self, c, numSlices=None): ...For example:
from pyspark import SparkContext, SparkConf if __name__ == "__main__": conf = SparkConf().setAppName("create").setMaster("local") sc = SparkContext(conf = conf) tuples = [("Lily", 23), ("Jack", 29), ("Mary", 29), ("James", 8)] pairRDD = sc.parallelize(tuples) pairRDD.coalesce(1).saveAsTextFile("out/pair_rdd_from_tuple_list") # return a new RDD that is reduced into `numPartitions` partitions. def coalesce(self, numPartitions, shuffle=False): ...Using the
coalesce()function to make sure we only have one final file before calling the saving method. -
From retular RDD
from pyspark import SparkContext, SparkConf if __name__ == "__main__": conf = SparkConf().setAppName("create").setMaster("local") sc = SparkContext(conf = conf) inputStrings = ["Lily 23", "Jack 29", "Mary 29", "James 8"] regularRDDs = sc.parallelize(inputStrings) pairRDD = regularRDDs.map(lambda s: (s.split(" ")[0], s.split(" ")[1])) pairRDD.coalesce(1).saveAsTextFile("out/pair_rdd_from_regular_rdd")This script read a string list to RDD, split each string and take the first element as key and the second element as value, and use the map function to create a Pair RDD.
Transformations on Pair RDDs
Because the Pair RDDs are still RDDs, they support the same functions as regular RDDs. The difference is we need to use functions that operate on tuples instead of individual elements.
-
filter():import sys sys.path.insert(0, '.') from pyspark import SparkContext, SparkConf from commons.Utils import Utils if __name__ == "__main__": conf = SparkConf().setAppName("airports").setMaster("local[*]") sc = SparkContext(conf = conf) airportsRDD = sc.textFile("in/airports.text") airportPairRDD = airportsRDD.map(lambda line: \ (Utils.COMMA_DELIMITER.split(line)[1], Utils.COMMA_DELIMITER.split(line)[3])) # filter function airportsNotInUSA = airportPairRDD.filter(lambda keyValue: keyValue[1] != "\"United States\"") airportsNotInUSA.saveAsTextFile("out/airports_not_in_usa_pair_rdd.text") -
map()andmapValues()Since the operations of pair RDDs usually keep the key unchanged, Spark provide themapValues()function to map the function only to the values.import sys sys.path.insert(0, '.') from pyspark import SparkContext, SparkConf from commons.Utils import Utils if __name__ == "__main__": conf = SparkConf().setAppName("airports").setMaster("local[*]") sc = SparkContext(conf = conf) airportsRDD = sc.textFile("in/airports.text") airportPairRDD = airportsRDD.map(lambda line: \ (Utils.COMMA_DELIMITER.split(line)[1], \ Utils.COMMA_DELIMITER.split(line)[3])) # mapValues function upperCase = airportPairRDD.mapValues(lambda countryName: countryName.upper()) upperCase.saveAsTextFile("out/airports_uppercase.text")A Popular Transformation Type: reduceByKey Aggregation
It is a common need to aggrigate the values with the same key in a Pair RDD. Similar to the
reduce()method on the regular RDD, there is a similar functionreduceByKey()for pair RDDs.
Note: Since a Pair RDD should have many keys, the reduceByKey() method is not designed as a regular action that returns a value. It will return a new RDD consisting of each key and the correspondent reduced value.
from pyspark import SparkContext, SparkConf
if __name__ == "__main__":
conf = SparkConf().setAppName("wordCounts").setMaster("local[3]")
sc = SparkContext(conf = conf)
lines = sc.textFile("in/word_count.text")
wordRdd = lines.flatMap(lambda line: line.split(" "))
wordPairRdd = wordRdd.map(lambda word: (word, 1))
wordCounts = wordPairRdd.reduceByKey(lambda x, y: x + y)
for word, count in wordCounts.collect():
print("{} : {}".format(word, count))
If we use the countByValue() action to do the work count, it will return a historgram map in the memory of the driver program. It is not a good approach to deal with large datasets.
Practice:
'''
Create a Spark program to read the house data from in/RealEstate.csv,
output the average price for houses with different number of bedrooms.
The houses dataset contains a collection of recent real estate listings in San Luis Obispo county and
around it.
The dataset contains the following fields:
1. MLS: Multiple listing service number for the house (unique ID).
2. Location: city/town where the house is located. Most locations are in San Luis Obispo county and
northern Santa Barbara county (Santa MariaOrcutt, Lompoc, Guadelupe, Los Alamos), but there
some out of area locations as well.
3. Price: the most recent listing price of the house (in dollars).
4. Bedrooms: number of bedrooms.
5. Bathrooms: number of bathrooms.
6. Size: size of the house in square feet.
7. Price/SQ.ft: price of the house per square foot.
8. Status: type of sale. Thee types are represented in the dataset: Short Sale, Foreclosure and Regular.
Each field is comma separated.
Sample output:
(3, 325000)
(1, 266356)
(2, 325000)
...
3, 1 and 2 mean the number of bedrooms. 325000 means the average price of houses with 3 bedrooms is 325000.
'''
```python
import sys
sys.path.insert(0, '.')
from pyspark import SparkContext, SparkConf
from pairRdd.aggregation.reducebykey.housePrice.AvgCount import AvgCount
if __name__ == "__main__":
conf = SparkConf().setAppName("avgHousePrice").setMaster("local[3]")
sc = SparkContext(conf = conf)
lines = sc.textFile("in/RealEstate.csv")
cleanedLines = lines.filter(lambda line: "Bedrooms" not in line)
housePricePairRdd = cleanedLines.map(lambda line: \
(line.split(",")[3], AvgCount(1, float(line.split(",")[2]))))
housePriceTotal = housePricePairRdd \
.reduceByKey(lambda x, y: AvgCount(x.count + y.count, x.total + y.total))
print("housePriceTotal: ")
for bedroom, avgCount in housePriceTotal.collect():
print("{} : ({}, {})".format(bedroom, avgCount.count, avgCount.total))
housePriceAvg = housePriceTotal.mapValues(lambda avgCount: avgCount.total / avgCount.count)
print("\nhousePriceAvg: ")
for bedroom, avg in housePriceAvg.collect():
print("{} : {}".format(bedroom, avg))
```
GroupByKey Transformation
Suppose we have a pair RDD that has keys with types X and values of type Y, this transformation will return a pair RDD that has X types of keys and Y types of values. Intuitively, the transformation will join the values with the same key as a iterable value following by a unique common key.
Create a Spark program to read the airport data from in/airports.text,
output the the list of the names of the airports located in each country.
Each row of the input file contains the following columns:
Airport ID, Name of airport, Main city served by airport, Country where airport is located, IATA/FAA code,
ICAO Code, Latitude, Longitude, Altitude, Timezone, DST, Timezone in Olson format
Sample output:
"Canada", ["Bagotville", "Montreal", "Coronation", ...]
"Norway" : ["Vigra", "Andenes", "Alta", "Bomoen", "Bronnoy",..]
"Papua New Guinea", ["Goroka", "Madang", ...]
import sys
sys.path.insert(0, '.')
from pyspark import SparkContext, SparkConf
from commons.Utils import Utils
if __name__ == "__main__":
conf = SparkConf().setAppName("airports").setMaster("local[*]")
sc = SparkContext(conf = conf)
lines = sc.textFile("in/airports.text")
countryAndAirportNameAndPair = lines.map(lambda airport:\
(Utils.COMMA_DELIMITER.split(airport)[3],
Utils.COMMA_DELIMITER.split(airport)[1]))
airportsByCountry = countryAndAirportNameAndPair.groupByKey()
for country, airportName in airportsByCountry.collectAsMap().items():
print("{}: {}".format(country, list(airportName)))
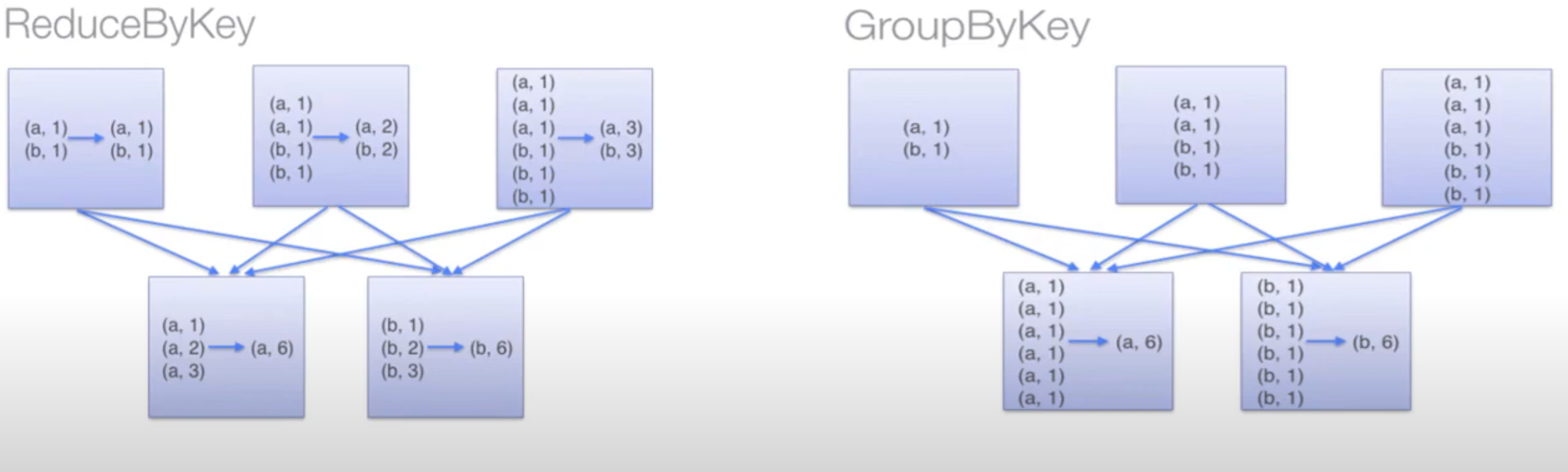
ReduceByKey Transformation
A short hand for the combination of groupByKey() plus reduce(), map(), or mapValues()
from pyspark import SparkContext, SparkConf
if __name__ == "__main__":
conf = SparkConf().setAppName('GroupByKeyVsReduceByKey').setMaster("local[*]")
sc = SparkContext(conf = conf)
words = ["one", "two", "two", "three", "three", "three"]
wordsPairRdd = sc.parallelize(words).map(lambda word: (word, 1))
wordCountsWithReduceByKey = wordsPairRdd \
.reduceByKey(lambda x, y: x + y) \
.collect()
print("wordCountsWithReduceByKey: {}".format(list(wordCountsWithReduceByKey)))
wordCountsWithGroupByKey = wordsPairRdd \
.groupByKey() \
.mapValues(len) \
.collect()
print("wordCountsWithGroupByKey: {}".format(list(wordCountsWithGroupByKey)))
ReduceByKey is much efficient then the groupByKey approach on large dataset because the data with common key would first be reduced into a smaller set on each node, while GroupBykey will not do the reduction before joining the different nodes result, which may cause extra computation.
SortByKey Transformation
Having sorted data is quite convinient for several tasks. We can sort a pair RDD if there is an ordering defined on the key. After the sorting, any subsequent call on the sorted Pair RDD to collect or save will return us ordered data.
import sys
sys.path.insert(0, '.')
from pairRdd.aggregation.reducebykey.housePrice.AvgCount import AvgCount
from pyspark import SparkContext, SparkConf
if __name__ == "__main__":
conf = SparkConf().setAppName("averageHousePriceSolution").setMaster("local[*]")
sc = SparkContext(conf = conf)
lines = sc.textFile("in/RealEstate.csv")
cleanedLines = lines.filter(lambda line: "Bedrooms" not in line)
housePricePairRdd = cleanedLines.map(lambda line: \
((int(float(line.split(",")[3]))), AvgCount(1, float(line.split(",")[2]))))
housePriceTotal = housePricePairRdd.reduceByKey(lambda x, y: \
AvgCount(x.count + y.count, x.total + y.total))
housePriceAvg = housePriceTotal.mapValues(lambda avgCount: avgCount.total / avgCount.count)
sortedHousePriceAvg = housePriceAvg.sortByKey()
# sorted by the decreasing order(default ascending=True)
# sortedHousePriceAvg = housePriceAvg.sortByKey(ascending=False)
for bedrooms, avgPrice in sortedHousePriceAvg.collect():
print("{} : {}".format(bedrooms, avgPrice))
Practice
Create a Spark program to read the an article from in/word_count.text,
output the number of occurrence of each word in descending order.
Sample output:
apple : 200
shoes : 193
bag : 176
Note:Use sortBy() action to select the value we need to sort by.
from pyspark import SparkContext, SparkConf
if __name__ == "__main__":
conf = SparkConf().setAppName("wordCounts").setMaster("local[*]")
sc = SparkContext(conf = conf)
lines = sc.textFile("in/word_count.text")
wordRdd = lines.flatMap(lambda line: line.split(" "))
wordPairRdd = wordRdd.map(lambda word: (word, 1))
wordToCountPairs = wordPairRdd.reduceByKey(lambda x, y: x + y)
# sortBy action, selecting the value to sort.
sortedWordCountPairs = wordToCountPairs \
.sortBy(lambda wordCount: wordCount[1], ascending=False)
for word, count in sortedWordCountPairs.collect():
print("{} : {}".format(word, count))
Reference:
Thanks for the amazing tutorial by Youtuber Analytics Excellence
The code can be found in the Github repository