Apache Spark - Data-Partitioning
Introduction
Data partitioning lets users control the layout of pair RDD across nodes. Using a proper data partitioning techinque may greately reduce the communication cost between the worker nodes by ensure the data that being accessed together are though the same node, which will significantly imporve the performance.
Review reduceByKey, groupByKey
In the previous learning, we have discussed that reduceByKey would do necessary computation before the communication between worker nodes while groupByKey would not. We should avoide using groupByKey as much as possible.
But we can also reduce the amount of shuffle for groupByKey. We can use hash partition to shuffle data with the same key at the same worker so that we can make partition using the key of the pair RDD.
partitionedWordPairRDD = wordPairRdd.partitionBy(4)
partitionedWordPairRDD.persist(StorageLevel.DISK_ONLY)
partitionedWordPairRDD.groupByKey().collect()
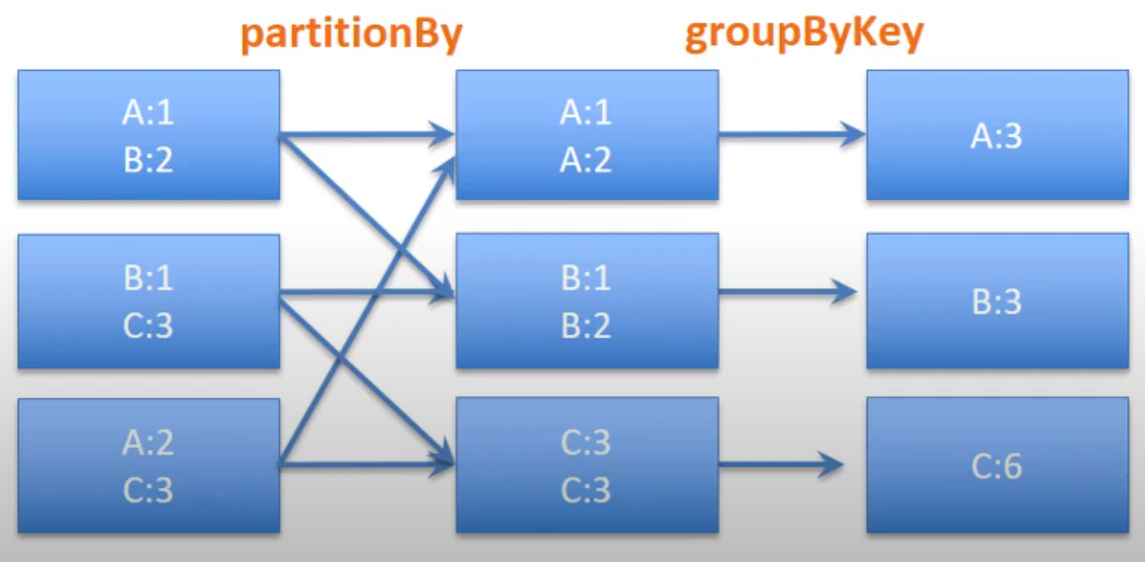
The data with the same key has been partitioned into the same worker node. Once we call the partition, the data has the same key hash value will only appear in the same worker node. Therefore, no matter how many time we call groupByKey(), there will not be random shuffled between keys.
Benefit of partitioning
By calling partition once, the susequence transformation will be operated on the partitioned result, which becomes more performative. It is important to persist the partiton result. Otherwise, it will repeat the partitioning again and again.
The following operations including shuffling will be benefited from partitioning:
- Join
- leftOuterJoin
- rightOuterJoin
- groupByKey
- reduceByKey
- combineByKey
- lookup
How reduceByKey benefits from partitioning?
Running reduceByKey() on a pre-partitioned RDD will let the values for each key computed locally on a single machine. Only the final locally reduced value would be sent to the master.
Operations which would be affected by partitioning
map() operations could cause the new RDD to forget the parent’s partitioning information. Because such operations could in theory, change the key of each element in the RDD. The result may not have a partitioner if the key have been changed by this operation. Spark will not check the map function to ensure if it retain the key.
mapValues() will retain the key, which could be a best practice when we doing map operation opun per-partitioned pair RDDs.
Reference:
Thanks for the amazing tutorial by Youtuber Analytics Excellence
The code can be found in the Github repository