Apache Spark - Join Operation
Introduction
Join operation can join two RDDs together. It is probably one of the most common operations on a pair RDD. The join operation has many types: leftOuterJoin, rightOuterJoin, crossJoin innerJoin, etc.
Inner Join
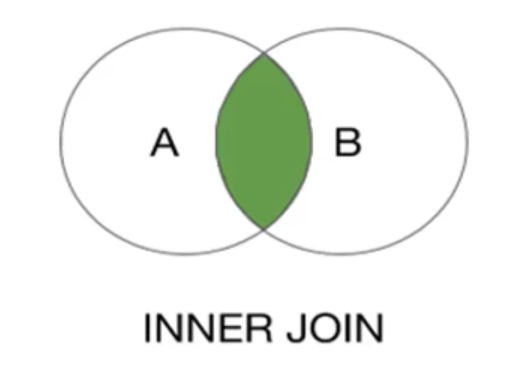
Only the same key of the 2 pair RDDs will be outputed. If there are multiple values for the same key in one of the inputs, the resulting pair RDD will have an entry for every possible pair of values with taht key from the two input RDDs.
def join(self, other, numPartitions=None):
...
Outer Joins
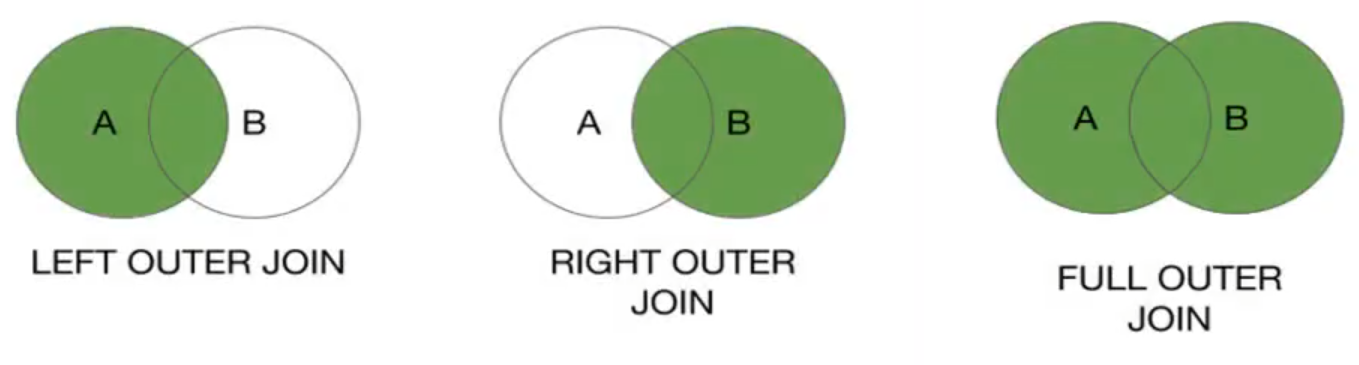
If we want to join 2 RDDs while keeping the keys that not exists in the other RDD. For example, we need to geather all the comments from users of 2 platforms while still want to keep the user who did’t have comments on the one of the platfrom. We need Outer joins that enables one fo the Pair RDDs can be missing the key. Meaning that the result RDD has entries for the source RDD.
Here is an example:
from pyspark import SparkContext, SparkConf
if __name__ == "__main__":
conf = SparkConf().setAppName("JoinOperations").setMaster("local[1]")
sc = SparkContext(conf = conf)
ages = sc.parallelize([("Tom", 29), ("John", 22)])
addresses = sc.parallelize([("James", "USA"), ("John", "UK")])
# Output: (`John`, (22, 'UK'))
join = ages.join(addresses)
join.saveAsTextFile("out/age_address_join.text")
# Output:
# ('Tom', (29, None))
# ('John', (22, 'UK'))
leftOuterJoin = ages.leftOuterJoin(addresses)
leftOuterJoin.saveAsTextFile("out/age_address_left_out_join.text")
# Output:
# ('John', (22, 'UK'))
# ('James', (None, 'USA'))
rightOuterJoin = ages.rightOuterJoin(addresses)
rightOuterJoin.saveAsTextFile("out/age_address_right_out_join.text")
# Output:
# ('Tom', (29, None))
# ('John', (22, 'UK'))
# ('James', (None, 'USA'))
fullOuterJoin = ages.fullOuterJoin(addresses)
fullOuterJoin.saveAsTextFile("out/age_address_full_out_join.text")
Best Practices
-
If both RDDs have duplicate keys, join operation can hugely expand the size of the data. Please perform a distinct or combineByKye operation to reduce the key space if possible.
-
Join operation may need large network transfers or even create a extremely large dataset that beyond our hardwear to handle.
-
Join operations are expensive since they require that corresponding keys from each RDD are located at the same partition so that they can be combined locally. If the RDDs do not have known partitioners, they will need to be shuffled so that both RDDs share a partitioner and data with the same keys lives in the same partitions.
Shuffled Hash Join
To join data, Spark require the data to be joined save in the same partition. The default implementation of join in Spark is shuffled hash join.
The shuffled hash join ensures that data on each partition will contain the same keys by partitioning the second dataset with the same default partitioner as the first so that the keys with the same hash value from both datasets are in the same partition.
While this approach always works, it can be more expensive than necessary because it requires a shuffle.
Avoid Shuffle
The shuffle can be avoided if both RDDs have a known partitioner. If they have the same partitioner, the data may be colocated. It can prevent network transfer. It is recommanded to call partitionby on the two join RDD with the same partitioner before joining them.
from pyspark.rdd import portable_hash
ages.partitionBy(20, partitionFunc = portable_hash)
addresses.partitionBy(20, partitionFunc = portable_hash)
Reference:
Thanks for the amazing tutorial by Youtuber Analytics Excellence
The code can be found in the Github repository