Apache Spark - SparkSQL Run on Amazon EMR Cluster
Introduction
This blog will show how to run a spark application on Amazon EMR(Elastic MapReduce) cluster. We are going to run our spark application on top of the Hadoop cluster and we will put the input data source into the Amazon S3.
Amazon EMR
Amazon EMR cluster provides a managed Hadoop framework that makes it easy, fast, adn cost-effecitve to process vast amounts of dat aacross dynamically scalable Amazon EC2 instances.
We can also run other popular distributed frameworks such as Apache Spark and HBase in Amazon EMR, and interact with data in other AWS data stores such as Amazon S3 and Amazon DynamoDB.
Amazon S3 (Simple Storage Service)
S3 is a distributed storage system and AWS’s equivalent to HDFS. The reason for storing our data in to a cloud platform instead of local computet is straightforward. We want to make sure that
-
Our data is comingfrom some distributed file system that can be accessed by every node on our spark cluster.
-
Our Spark application doesn’t assume that our input data sits somewhere on our local disk because that will not scale.
By saving our input data source into S3, each spark node deployed on the EMR cluster can read the input data source form S3.
Experiment
Note: Since the reference tutorial is from 2020, the AWS web page has changed a lot at 2024. But the key process remains the same.
Create EMR Cluster
Log into your aws account and search for EMR, create a EMR cluster.
-
Use a spark application bundle.
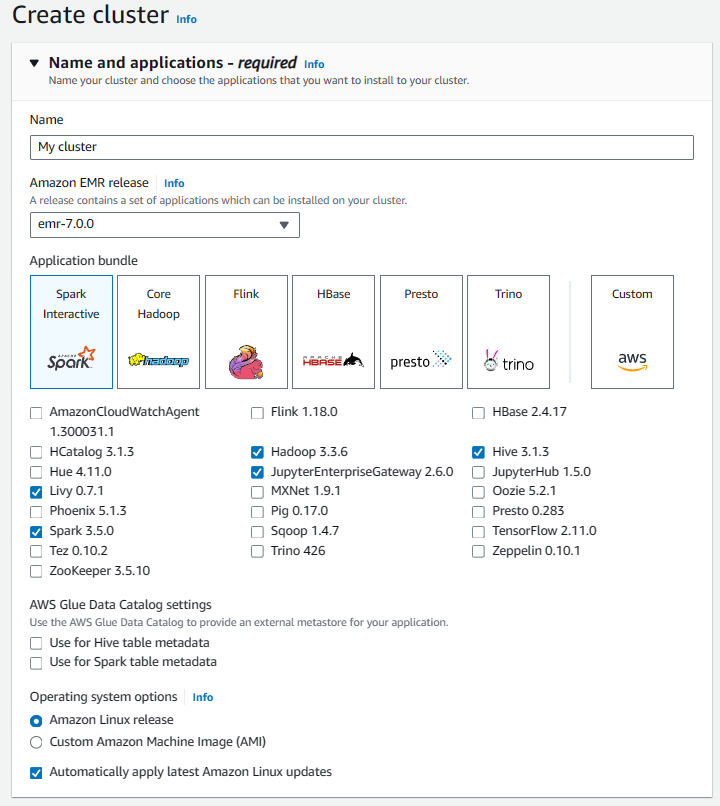
- Choose the types of instance for Master, Core Task Nodes.
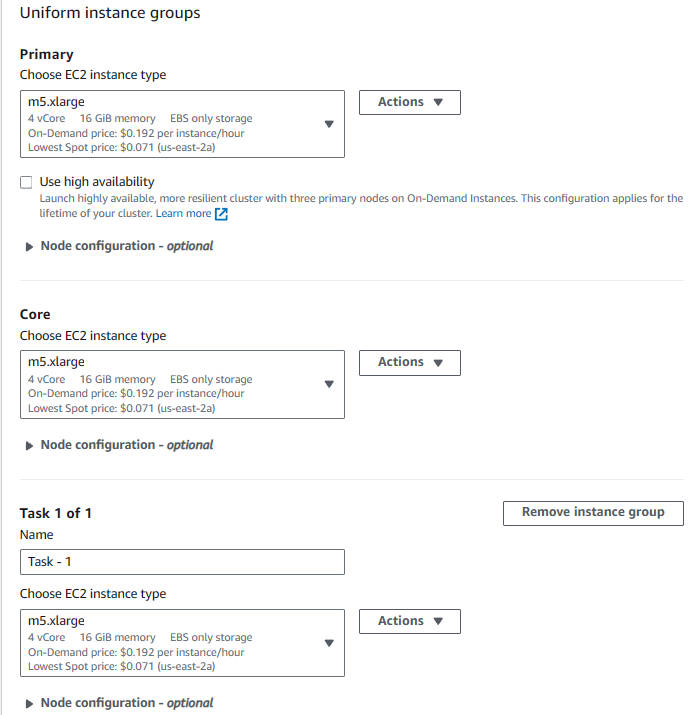
- Select EC2 key pair. I would be used when connecting using SSH. It is necessary configuration for connecting to the cluster.
 Then, we can create the cluster. It takes 10 - 15 mins to create.
Then, we can create the cluster. It takes 10 - 15 mins to create.
Update security setting to enable SSH connection
- Open the security groups for the master node:
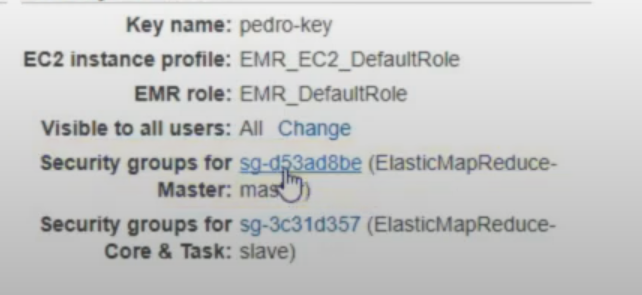
- Click the master group, and hit
editunder the Inbound.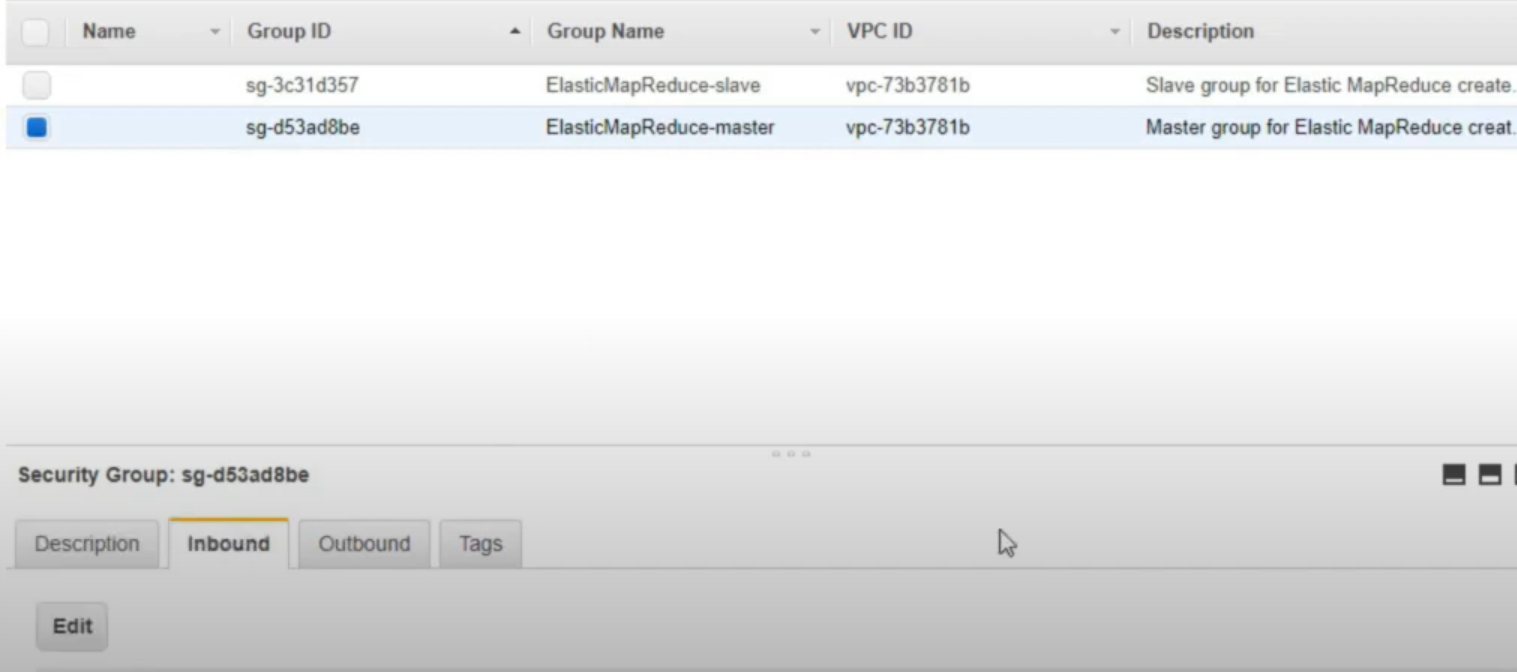
- Add Rule. Type is SSH and the Source is
Anywhere. Note:Anywhereallows all the Ip address to connect, which would never be used in a product environment. Usually we will set a allowed IP range for the connection.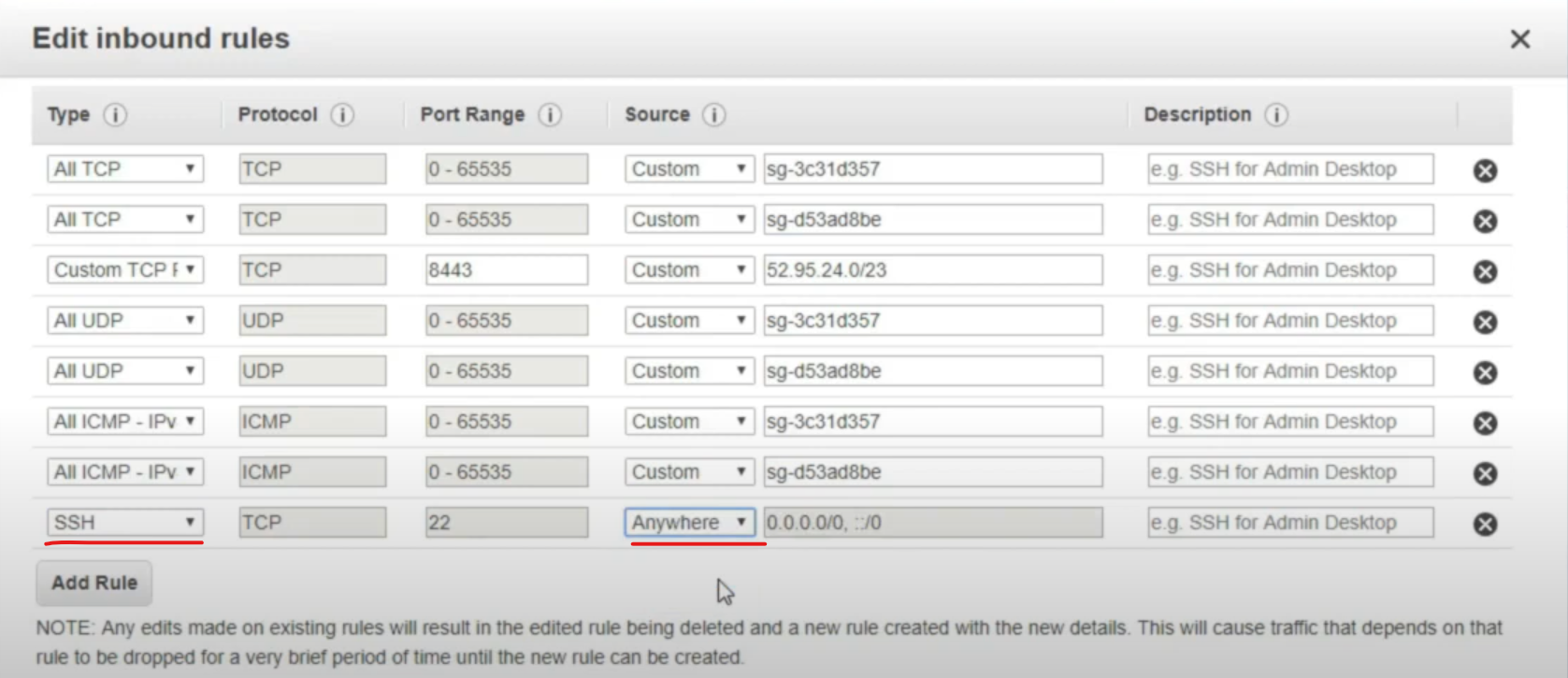
Upload Dataset and script
- Create a new S3 bucket.
- Upload the csv file to the new created S3 bucket.
Update and Run Spark application script.
- Modified the local application script.
from pyspark.sql import SparkSession
AGE_MIDPOINT = "age_midpoint"
SALARY_MIDPOINT = "salary_midpoint"
SALARY_MIDPOINT_BUCKET = "salary_midpoint_bucket"
if __name__ == "__main__":
# remove the master("local[1]") to enable running on multiple machine.
#session = SparkSession.builder.appName("StackOverFlowSurvey").master("local[1]")getOrCreate()
session = SparkSession.builder.appName("StackOverFlowSurvey").getOrCreate()
# set the log level to ERROR, avoid too much info log output.
sc = session.sparkContext
sc.setLogLever('ERROR')
dataFrameReader = session.read
responses = dataFrameReader \
.option("header", "true") \
.option("inferSchema", value = True) \
# .csv("in/2016-stack-overflow-survey-responses.csv")
.csv("s3n://{bucket_name}/{file_name}/2016-stack-overflow-survey-responses.csv")
# the spark will load file from s3
print("=== Print out schema ===")
responses.printSchema()
- Then upload the python script to S3 bucket.
Connect and run the Spark application using SSH
- Find the Master public DNS of the EMR we created.

-
Connect to the master machine using PuTTY or simple ssh. Add the key pair to the connection.
-
After succefully connected, use the terminal to fetch the python script to the master machine for execution.
aws s3 cp s3://{bucket_name}/{file_name}.py -
Then, use spark-submit to run the application
spark-submit {python_script_name}.py
Now we know how to run a Spark cluster on a remote machine!
Reference:
Thanks for the amazing tutorial by Youtuber Analytics Excellence
The code can be found in the Github repository