Apache Spark - SparkSQL Running in Clusters
Introduction
Our previous experiments are all on the local mode. But the point of using spark is to add more worker nodes and running in cluster mode to scale computation.
Writing applications for parallel cluster execution uses the same API we have already learned in previous experiments. The spark programs we have written so far can run on a cluster out of the box. This allows us to repidly prototype our spark applications on smaller dataset locally, then run unmodified code against a large dataset and potentially on a large cluster.
Running Spark in the Cluster Mode.
In distributed mode, spark uses a Master-Slave pattern with one central coordinator (driver program) and several distributed workers (Executors). A driver program runs in a Java process, and the other executors run in other Java process respectively.
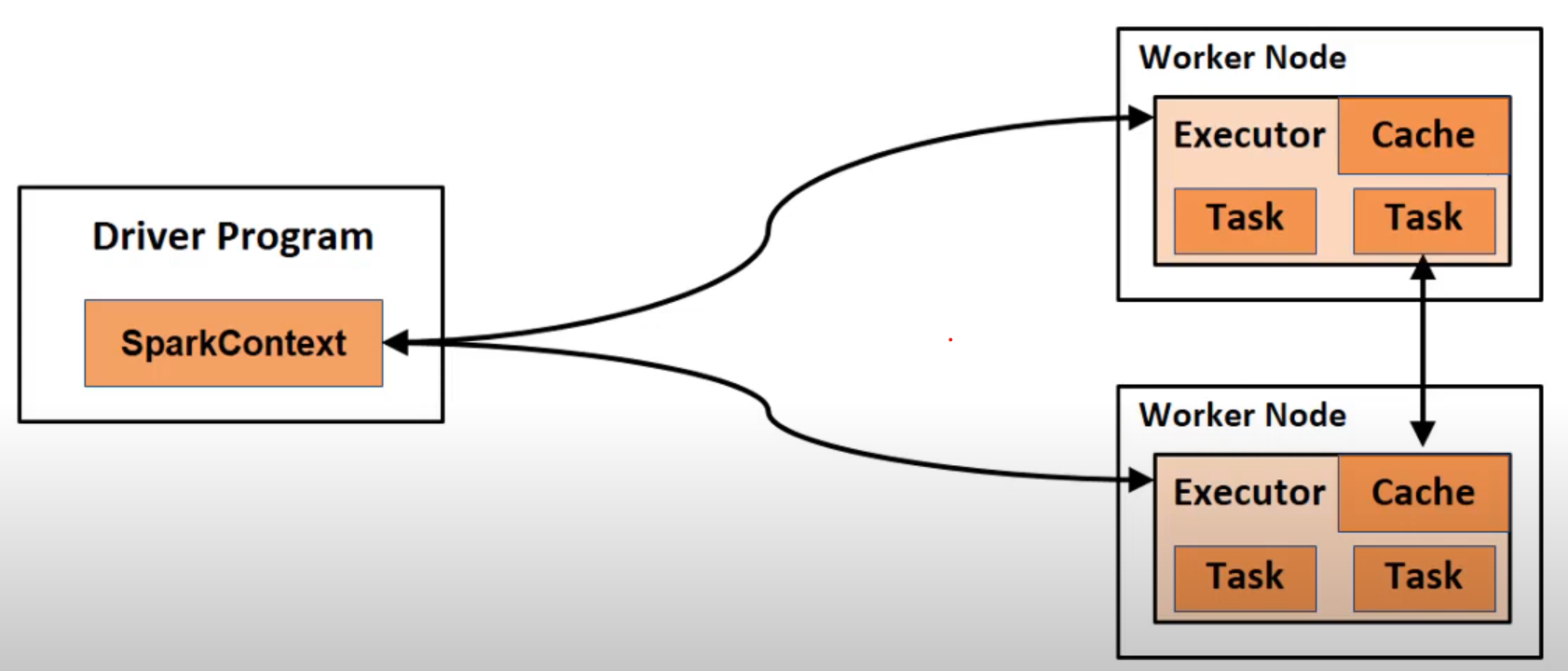
The above image shows the high-level overview about how the spark application runs in a cluster. In reality, the spark application runs in a saddle machine internally called Cluster Manager.
The machine where the application (driver process) is running called the driver node. The other machine where the Cluster Manager is running, called the master node. Alongside, in each of the machines in the cluster, there is a worker process reports the available resources in its node to the master node.
Specifically, the spark contacts connect cluster managers who allocate resources across applications. Once connected, spark acquires executors on nodes in the cluster, which are process that run computations and store data for our application.
Cluster Manager
The cluster manager is a pluggable component in Spark. Spark is packaged with a build-in cluster manager called the Standalone Cluster Manager. There are other types of Spark manager such as:
-
Hadoop Yarn: A resource management and scheduling tool for a Hadoop MapReduce cluster. It has a manificent support for HDFS with data locality. Hadoop Yarn allows us to run spark on a hadoop clust er.
-
Apache Mesos: Centralized fault-tolerant cluster manager and global resource manager for your entire data center. It allows spark to run on hardware clusters managed by apache mesos.
The cluster manager abstracts away the underlying cluster environment so that we can use the same unified high-level Spark API to write Spark program which can run on different clusters.
We can use spark-submit to submit an application to the cluster. The spark-submit can use all types of cluster manager for a uniform interface. We don’t have to create configuration for each one. It allows us to connect to different cluster manager and control how many resource each application get.
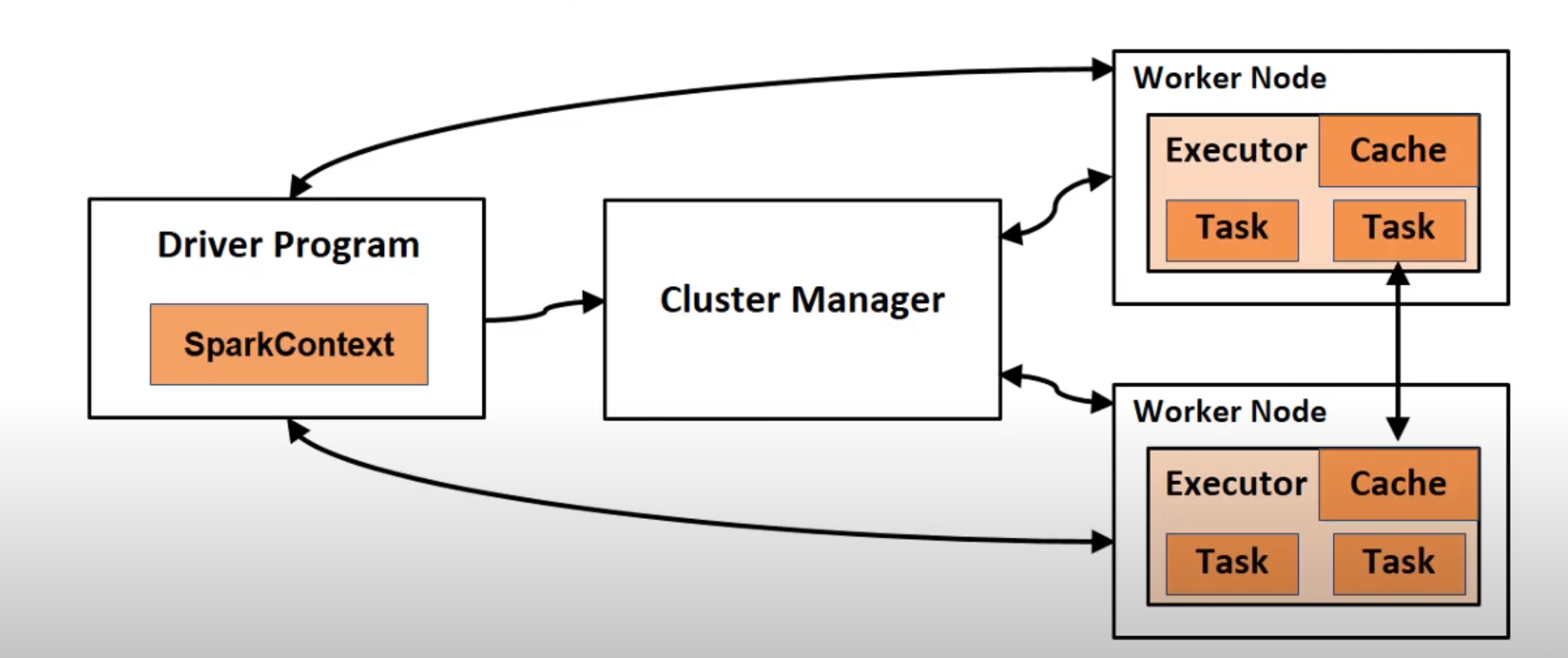
Workflow of running Spark Application on a Cluster
- The user submit an application using
spark-submit. - Spark-submit launches the driver program and invokes the main method specified by the user.
- The driver program contacts the cluster manager to ask for resources to start executors.
- The cluster manager launches executors on befalf of the driver program.
- The driver process runs through the user application. Based on the RDD or dataframe operations in the program, the driver sends work to executors in the form of tasks.
- Tasks run on executor processes to compute and save results.
- If the driver’s main method exits or it calls SparkContext.stop(), it will terminate the executors.
spark-submit Options:
spark-submit \
--executor-memory 20G \
--total-executor-cores 100\
path/to/application.py
We can config the executor memory and the total executor cores for the application we will run. Make sure the memory is not exceeding the total limite of each excutor node.
Benefits:
-
We can run Spark applications from a command line or execute the script periodically using a Cron job or other scheduling service.
-
Spark-submit script is an available script on any operating system that supports Java. You can develop your Spark application on Windows machine and upload the py script to a Linux cluster and run the spark-submit script on the Linux cluster.
Reference:
Thanks for the amazing tutorial by Youtuber Analytics Excellence
The code can be found in the Github repository